
Spring Boot Microservices auf Kubernetes
Kürzlich bin ich auf ein aktuelles Video gestoßen, was sich mit der Frage beschäftigt: Muss ich 2025 noch Kubernetes lernen?
Natürlich könnte ich meine Microservices auch ganz einfach per Serverless oder Managed Container Service in der Cloud deployen. Das wäre einfacher und weniger Aufwand für mich. Warum sollte ich mir dann noch den Stress antun und Kubernetes lernen?
Das Problem an der Bequemlichkeit bei Serverless auf der Cloud ist der “Vendor Lock-in”. Ich bin von AWS (oder Google, oder Azure) abhängig - und das ist nie gut.
Kubernetes hingegen läuft überall. Ich kann es auf AWS laufen lassen, bei europäischen Anbietern und sogar in meinem eigenen Keller auf Rasperry Pis.
So weit will ich hier nicht gehen. Aber ich möchte auch die Freiheit haben, meinen Anbieter zu wechseln, ohne die gesamte Architektur neu zu erfinden.
Also, ich habe mich dazu entschieden - auch wenn es initial ein Mehraufwand bedeutet - Kubernetes zu lernen und zur Übung zwei Microservices (lokal) zu deployen.
Kubernetes (auch K8s genannt) ist der Standard der Container-Orchestrierung. Es ist ein Open-Source-Tool, mit dem sich Anwendungen einfach skalieren lassen. Vorteile sind:
- Hohe Verfügbarkeit: Das Ziel ist “Zero Downtime”. Kubernetes tauscht laufende Container selber aus, ohne dass Nutzer etwas merken.
- Skalierbarkeit: Wenn meine App unerwartet viele Anfragen bearbeiten muss, fährt Kubernetes selber Container hoch, um die Last abzufangen.
- Selbstheilung und Rollbacks: Wenn ein Deployment schiefgeht, kann Kubernetes selbständig ein Rollback durchführen. Also die letzte (funktionierende) Version zu Verfügung stellen.
Oft wird gesagt, dass Kubernetes eine steile Lernkurve hat. Es umfasst tatsächlich viele Konzepte, die erstmal schwierig zu fassen sind. Hier versuche ich nicht alle Konzepte zu berücksichtigen, sondern einen groben Überblick zu geben, wie ein Deployment von Microservices (Spring Boot) ungefähr aussehen kann.
Kubernetes Grundlagen
Pods: Das ist die kleinste Einheit in Kubernetes. Ein Pod stelle ich mir äquivalent zu einem Container vor. Zwar können auch mehrere Container in einem Pod laufen, dieses Szenario sollte aber vermieden werden. Jeder Container sollte in der Regel seinen eigenen Pod bekommen. Pods haben ihre eigene IP-Adresse. Als Manager des Kubernetes-Clusters habe ich selten direkt mit Pods zu tun.
Nodes: Nodes sind die Maschinen, auf denen die Pods laufen. Es gibt zwei Arten von Nodes: Worker Nodes und Master Nodes. Auf den Worker Nodes laufen die tatsächlichen Pods, also die containerisierten Anwendungen. Die Master Nodes sind für die Verwaltung des Clusters verantwortlich. Hier laufen keine Anwendungs-Container. Als Manager des Klusters interagiere ich mit den Master Nodes, die meine Anweisungen an die Worker Nodes weitertragen.
Services: Ein Service ist eine Abstraktion des einzelnen Pods. Da Pods jederzeit hoch- und runtergefahren werden können, ändern sich die IP-Adressen der Pods ständig. Daher ist es sinnlos, sich die IP-Adressen zu merken. Ein Service ist die Abstraktion, die es ermöglicht, dass Apps miteinander über stabile Service-Namen miteinander kommunizieren. Der Service leitet die Anfragen dann an die entsprechenden Pods weiter.
Deployments: Ein Deployment beschreibt den gewünschten Zustand einer Anwendung. Beispielsweise definiere ich in einem Deployment die Anzahl der Instanzen meiner Anwendung. Das Deployment sorgt dann dafür, dass immer drei Pods laufen. Fällt einer aus, wird ein neuer gestartet. Deployments werden verwendet für stateless Anwendungen - also unsere Spring Boot Microservices. Stateful Anwendungen, wie Datenbanken sollten anders behandelt werden und werden hier nicht weiter thematisiert.
ConfigMap: In ConfigMaps definiere ich die Konfigurationen meiner Anwendung (die nicht geheim sind). Beispielsweise Datenbank-URLs oder Features-Flags.
Secrets: Hier definiere ich geheime Daten, wie Passwörter oder API-Keys. Die Werte werden von Kubernetes allerdings nur Base64-kodiert, was nicht unbedingt sicher ist. Für echte Produktions-Umgebungen sollte aber ein echter Secret Manager (z.B. von AWS) genutzt werden.
Ich, als Manager des Kubernetes-Clusters, steuere die Kubernetes-Objekte über das kubectl CLI-Tool. Hier kann ich den Zustand meines Clusters abfragen, Objekte erstellen, bearbeiten und löschen. Um komplexe Kubernetes-Objekte zu definieren, schreibe ich YAML-Dateien.
Um das Ganze zu testen, habe ich zwei simple Spring Boot Services:
Auth Service: Dieser kümmert sich um die Registrierung, Login usw.
Product Service: Dieser liefert eine Liste von Produkten, aber nur, wenn der Auth Service (via Token) die Anfrage validiert.
Kubernetes-Integration in Spring Boot
Damit eine Spring Boot App weiß, dass sie in einem Kubernetes-Cluster deployt wird, braucht sie das Projekt “Spring Cloud Kubernetes”. Hier sind ein paar Abhängigkeiten, die gebraucht werden:
- spring-boot-startet-actuator: Diese Abhängigkeit ist nicht Teil von Spring Cloud. Trotzdem ist sie hier notwendig. Actuator stellt Health-Endpunkte bereit, beispielsweise ‘/actuator/health/liveness’. Kubernetes pingt diese Endpunkte an, um den Zustand der Anwendung zu erfahren.
- spring-cloud-starter-kubernetes-all: Diese Abhängigkeit bündelt alle wichtigen Abhängigkeiten für die Entwicklung. Für die Produktion sollte man das in die Einzelteile zerlegen.
- spring-cloud-starter-kubernetes-client: Diese Abhängigkeit ermöglicht, dass meine Services miteinander reden können. Wenn der Product-Service beispielsweise mit dem Auth-Service reden will, fragt dieser Client den Kubernetes API Server dem Auth Service.
- spring-cloud-starter-kubernetes-config: Mit dieser Abhängigkeit liest meine Spring App automatisch die Konfigurationen aus den Kubernetes ConfigMaps und Secrets. Die Werte tauchen dann als Properties in der Spring-Umgebung auf und können genutzt werden.
In der Spring Boot Anwendung lege ich neben der application.yml Datei auch noch eine application-kubernetes-yml Datei an. Diese wird automatisch geladen, wenn das Profil “kubernetes” aktiv ist. In dieser Datei aktiviert man dann z.B. die Service Discovery mit folgender Konfiguration:
spring:
cloud:
kubernetes:
enabled: true
discovery:
enabled: true
all-namespaces: falseSchritte: Spring Boot ins Cluster bringen
Schritt 1 - Dockerfile:
Zuerst brauche ich ein Docker-Image. Der folgende Code zeigt ein mehrstufiges Dockerfile:
# Stage 1: Builder - Extract layered JAR
FROM eclipse-temurin:21-jdk-jammy AS builder
WORKDIR /builder
COPY gradlew .
COPY gradle gradle
COPY build.gradle .
COPY settings.gradle .
COPY src src
RUN ./gradlew clean bootJar -x test
# Stage 2: Runtime - Create optimized final image
FROM eclipse-temurin:21-jre-jammy
WORKDIR /app
# Create non-root user
RUN addgroup --system spring && adduser --system spring --ingroup spring
# Copy extracted layers (order matters for caching)
COPY --from=builder /builder/build/libs/*.jar app.jar
USER spring:spring
EXPOSE 8000
ENTRYPOINT ["java", \
"-Dspring.profiles.active=kubernetes", \
"-XX:MaxRAMPercentage=75.0", \
"-XX:+UseParallelGC", \
"-XX:ActiveProcessorCount=2", \
"-jar", "app.jar"]Was passiert hier?
- Stage 1 (builder): Ich baue das Image auf einem JDK-Image auf, kopiere dann erst die Build-Dateien (damit Docker das Caching nutzt, wenn sich nur der Code ändert) und baue das JAR.
- Stage 2 (runtime): Ich baue auf einem schlanken JRE-Image (ich brauche in dieser Stufe keinen Compiler mehr) auf und erstelle einen User “spring”, damit die App nicht als root läuft. In dieser Stufe nutze ich dann das erstellte JAR auf Stage 1.
- ENTRYPOINT: Hier starte ich die App mit ein paar Besonderheiten:
- spring.profiles.active=kubernetes: führt zum Laden der application-kubernetes.yml Datei
- die XX-Flags: Gibt Anweisung zum Feintuning für RAM, Garbage Collector, CPUs in einer Container-Umgebung
Schritt 2 - Kubernetes-Dateien definieren:
Jetzt definiere ich die YAML-Dateien. Ich habe mich (auf Bequemlichkeit) entschieden, die Konfiguration nicht in ConfigMaps zu packen, sondern fest in die App. In echten Projekten sollte das anders gemacht werden!
Für jeden Microservice brauchen wir ein Secret, ein Service und ein Deployment. Hier am Beispiel des auth-service.
Secret:
apiVersion: v1
kind: Secret
metadata:
name: auth-service-secret
namespace: microservices
type: Opaque
stringData:
SPRING_DATASOURCE_URL: ""
SPRING_DATASOURCE_USERNAME: ""
SPRING_DATASOURCE_PASSWORD: ""In dieser Datei definiere ich die Umgebungsvariablen, die ich in der Spring Boot Anwendung nutze.
Service:
apiVersion: v1
kind: Service
metadata:
name: auth-service
namespace: microservices
labels:
app: auth-service
spec:
type: ClusterIP
selector:
app: auth-service
ports:
- name: http
port: 8000
targetPort: 8000Hier ist die YAML-Datei für den Service des auth-service. Wie fast jede Kubernetes YAML-Datei ist sie in zwei Teile geteilt: Metadata und Spec:
- Metadata: Hier gebe ich den Namen, Namespace und Labels an. Labels sind die entscheidenden Schlüssel-Wert-Paare, mit denen Kubernetes referenziert.
- Spec: Hier definiere ich den eigentlichen Service:
- type: Cluster IP: Das ist der Standard-Modus und bedeutet, dass der Service nur innerhalb des Clusters erreichbar ist.
- selector: Das sagt dem Service, an welche Pods er Anfragen weiterleiten soll. In diesem Fall an die, die das Label app: auth-service tragen (Diese Labels werden im Deployment für die Pods definiert)
- ports: Hier werden die Ports definiert. port: 8000 ist der Port, auf dem der Service selber erreichbar ist. targetPort: 8000 ist der Port, auf dem der Container im Pod erreichbar ist.
Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: auth-service
namespace: microservices
labels:
app: auth-service
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: auth-service
template:
metadata:
labels:
app: auth-service
spec:
containers:
- name: auth-service
image: auth_service:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8000
protocol: TCP
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "1000m"
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 1
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 1
startupProbe:
httpGet:
path: /actuator/health/liveness
port: 8000
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 5
failureThreshold: 30
successThreshold: 1
restartPolicy: Always
terminationGracePeriodSeconds: 30Diese YAML-Datei definiert das Deployment. Es gibt wieder die klassische Aufteilung in Metadata (Name, Labels, …) und Spec.
Im Spec definiere ich den gewünschten Zustand:
- replicas: 2: Damit sage ich Kubernetes, dass ich immer zwei identische Pods dieser App laufen haben will. Fällt ein Pod aus, soll Kubernetes sofort einen neuen starten.
- strategy: type: RollingUpdate: Diese Konfiguration führt zu Zero Downtime. Statt alles auf einmal neu zu starten, werden die Pods nacheinander, rollierend ausgetauscht.
- maxSurge: 1: Das sagt Kubernetes, dass er während eines Updates ein Pod mehr als die gewünschten zwei Pods erstellen darf. Es gibt dann also kurzfristig drei Pods.
- maxUnavailable: 0: Das sagt Kubernetess, dass niemals ein Pod abgeschaltet wird, bevor der neue läuft. Es müssen immer mindestens zwei verfügbar sein.
Im template wird die Pod-Vorlage definiert. Das ist die Definition für jeden einzelnen Pod, den das Deployment erstellt. Die labels hier sind extrem wichtig - diese werden in dem oben beschriebenen Service referenziert.
In der Pod-Vorlage selbst lege ich fest:
- image: auth_service:latest: Hier definiere ich, welches Docker-Image verwendet werden soll. In diesem Fall habe ich das Image lokal gebaut. Ansonsten würde hier die Image-Registry stehen
- ports: containerPort: 8000: Der Container im Inneren des Pods hört auf Port 8000
- resources: Hier definiere ich limits und requests. Requests sind die garantierten Ressourcen. Hier lege ich fest, dass der Pod mindestens 512MB RAM und einen viertel CPU-Kern braucht, um überhaupt hochzufahren. In den limits lege ich die Obergrenze fest. Hier sage ich, dass wenn ein Pod jemals mehr als 1GB RAM oder 1 CPU-Kern benötige, Kubernetes diesen Pod herunterfahren darf. Damit verhindere ich, dass ein Pod die gesamte Maschine (Node) lahmlegt.
- Health Checks (Probes): Hier sage ich Kubernetes, wo welches Endpunkt für welchen Health Check liegt:
- startupProbe: Kubernetes checkt diesen Endpunkt, um zu prüfen, ob der Pod als hochgefahren wird oder als fehlgeschlagen markiert wird.
- livenessProbe: Dieser Health Check startet, nachdem der startupProbe erfolgreich war. Kubernetes fragt diesen Endpunkt ab, um zu prüfen, ob ein Pod noch läuft.
- readinessProbe: Dieser Health Check läuft parallel und fragt den Pod, ob dieser bereit ist, Anfragen zu empfangen.
Ingress:
Bisher sind die Services nur vom Typ ClusterIP, also nur innerhalb des Clusters erreichbar. Um aber Anfragen von außerhalb des Clusters, also einer mobile App oder Web Clients zuzulassen, brauchen wir einen Ingress.
Ein Ingress ist ein Regelwerk. Man braucht einen Ingress Controller (z.B. Nginx), der die Regeln umsetzt.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: microservices-ingress
namespace: microservices
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
ingressClassName: nginx
rules:
- host: dev.backend
http:
paths:
- path: /api/v1/auth(/|$)(.*)
pathType: ImplementationSpecific
backend:
service:
name: auth-service
port:
number: 8000Diese YAML-Datei zeigt die Ingress-Konfiguration, die entscheidet, welcher Traffic von außen rein darf. Es wird wieder aufgeteilt in Metadata und Spec:
Im Metadadata-Block definiere ich neben Namen und Namespace die annotations:
- *nginx.ingress.kubernetes.io/use-regex: "true"*: Das ist der Befehl an NGINX zu sagen, dass die Pfade der Anfragen kein Text, sondern eine Regex-Ausdrücke sind
- nginx.ingress.kubernetes.io/rewrite-target: /$2: Das bedeutet, dass nur der zweite Teil des Requests hinter dem Regex-Ausdrück als neuer Request an den Service weitergeleitet wird
Im Spec definiere ich folgendes:
- ingressClassName: nginx: Hier definiere ich, dass der Ingress-Controller NGINX sein soll
- rules: Hier definiere ich den Host (dev.backend) und die path-Regeln. Beispielhaft zeige ich hier, dass alle Anfragen mit ‘/api/v1/auth’ an den Service weitergeleitet werden soll. Eine Anfrage mit dem Path: ‘/api/v1/auth/login’ wird an den Auth Service weitergeleitet mit dem Path: ‘/login’
Damit dev.backend auf meinem lokalen Rechner funktioniert, muss ich meine ‘/etc/hosts’-Datei bearbeiten und das eintragen:
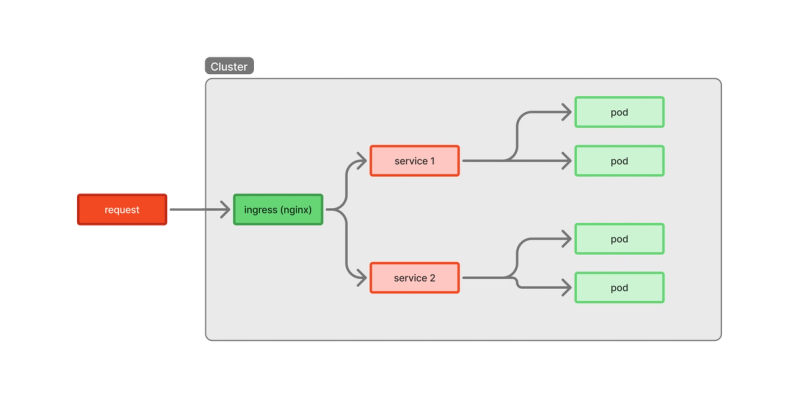
127.0.0.1 dev.backendDer Weg eines Requests:
- Ich mache einen Request an ‘http://dev.backend/api/v1/auth/login’.
- Meine hosts-Datei schickt das an 127.0.0.1. Hier liegt mein Kubernetes-Cluster
- Der Ingress-Controller (NGINX) fängt es ab.
- Der Request wird an den auth-service mit dem Pfad: ‘/login’ weitergeleitet.
- Der Service auth-service nimmt ‘/login’ entgegen und leitet es an einen der Pods weiter
- Der Pod verarbeitet ‘/login’ und schickt die Antwort zurück
RBAC (Der Teil, den ich lokal ignoriert habe, der aber in realen Projekten nicht ignoriert werden sollte)
RBAC (Role-Bases Access Control) legt fest, wer was im Cluster tun darf. Das Ziel ist das Prinzip der geringsten Rechte (Principle of Least Privilege). Niemand, auch keine App, sollte mehr Rechte haben, als er unbedingt braucht. Die Hauptkonzepte von RBAC sind:
Role: Das ist ein Satz von Regeln innerhalb eines Namespace (z.B. wird definiert, dass die Rolle im Namespace ‘microservices’ Pods lesen darf)
ClusterRole: Das ist ein Satz von Regeln für das gesamte Cluster (z.B. wird definiert, dass die Rolle alle Nodes auflisten darf)
RoleBinding: Ein RoleBinding weist eine Role einem “Subjekt” (User, Gruppe oder ServiceAccount) innerhalb eines Namespaces zu. RoleBindings können auch ClusterRoles nutzen. Die in dem ClusterRole vergebenen Rechte gelten dann aber trotzdem nur für den jeweiligen Namespace, auf dem das RoleBinding angewendet wird.
ClusterRoleBinding: Ein ClusterRoleBinding weist eine ClusterRole einem Subjekt im gesamten Cluster zu.
Ein “Subjekt” kann ein menschlicher Nutzer sein oder ein ServiceAccount. Ein ServiceAccount wird einem Prozess, der innerhalb eines Pods läuft, zugeschrieben. Diese Pod hat dann die Rechte, die in der jeweiligen Role definiert wurden.
Für die Spring Boot Apps würde ich Folgendes tun:
1. Einen ServiceAccount erstellen:
apiVersion: v1
kind: ServiceAccount
metadata:
name: auth-service-sa
namespace: microservices2. Eine Role erstellen: Die App muss Services, Endpoints, ConfigMaps und Secrets lesen können:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: auth-service-role
namespace: microservices
rules:
- apiGroups: [""]
resources: ["configmaps", "secrets", "services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]3. Ein RoleBinding erstellen: Hier wird der ServiceAccount und die Role miteinander verknüpft, sodass der ServiceAccount die in der Role definierten Rechte erhält.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: auth-service-rolebinding
namespace: microservices
subjects:
- kind: ServiceAccount
name: auth-service-sa
namespace: microservices
roleRef:
kind: Role
name: auth-service-role
apiGroup: rbac.authorization.k8s.io4. Im Deployment referenziere ich dann den ServiceAccount. Im spec.template.spec des Deplyoments füge ich hinzu: serviceAccountName: auth-service-sa.
Fazit und Ausblick
Das war’s schon. Ich habe gezeigt, wie man eine sehr einfache Spring Boot Microservice-Anwendung auf Kubernetes lokal via Minikube deployt.
Ist Kubernetes also noch wichtig? Ja, definitiv. Auch wenn Cloud-Services einfacher sind, ist man mit Serverless Deployments meiner Meinung nach zu sehr an den jeweiligen Cloud Provider gekoppelt. Mit Kubernetes habe ich immer noch die Vorteile der Skalierung, nur bin ich unabhängiger. Im Endeffekt wird mein Kubernetes Cluster zwar wahrscheinliche trotzdem auf der Cloud laufen, ich habe aber theoretisch die Möglichkeit, das Cluster auf eigenen Servern laufen zu lassen. Noch ein Vorteil ist, dass es so etwas wie Serverless auf europäischen Cloud Providern noch nicht gibt. Hier werden aber Managed Kubernetes Services angeboten.
Und Spring Boot? Ist wahrscheinlich nicht die modernste Technologie, aber ein extrem solider Weg, Microservices zu bauen. Und mit dem Spring Cloud Ökosystem gibt es eine super Integration mit Kubernetes.